Installing Hadoop Cluster
I have four VM machines in dev and I want to configure my own hadoop cluster to use as a tool and analysis.
I’m going to follow the general process out lined by hadoop’s instructions and yahoo help, here and here.
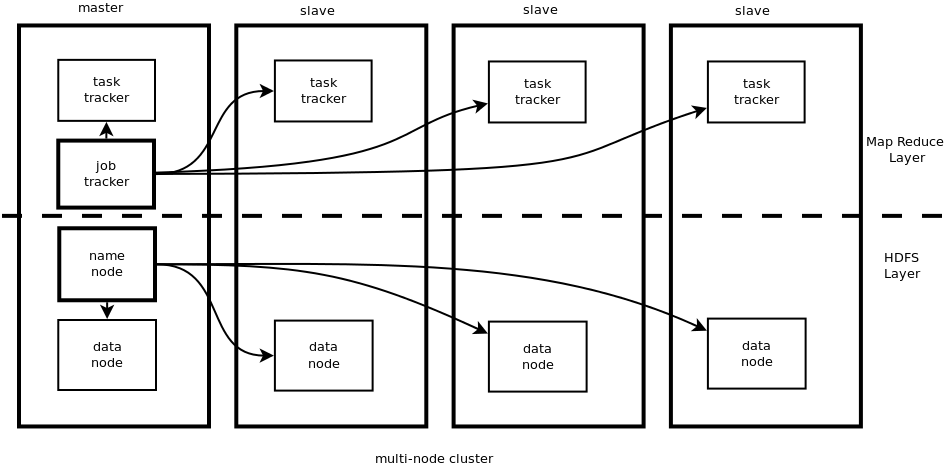
This is what the final setup will look like
Prework
I found that hadoop has default ports that need to be opened between servers before it will work.
# Add local ssh support on each machine
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# Configure master to talk to each slave.
a.brlamore@master:~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub a.brlamore@slave
# Configure each slave to talk to the master.
a.brlamore@slave:~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub a.brlamore@master
Important Directories
| Directory | Description | Suggested location |
|---|---|---|
| HADOOP_LOG_DIR | Output location for log files from daemons | /var/log/hadoop |
| hadoop.tmp.dir | A base for other temporary directories | /tmp/hadoop |
| dfs.name.dir | Where the NameNode metadata should be stored | /home/hadoop/dfs/name |
| dfs.data.dir | Where DataNodes store their blocks | /home/hadoop/dfs/data |
| mapred.system.dir | The in-HDFS path to shared MapReduce system files | /hadoop/mapred/system |
Configuration
Hadoop Home
HADOOP_HOMEis set to/u01/accts/a.brlamore/tmp/hadoop-0.21.0- I’ve put in a request for root access so I can change this to
/opt/hadoop
Edit Slaves file
vi /conf/slaves
ali-graph002.devapollogrp.edu
ali-graph003.devapollogrp.edu
ali-graph004.devapollogrp.edu
Site Configuration
- Set the
JAVA_HOMEinconf/hadoop-env.shtoexport JAVA_HOME=/usr/java/default - Set values in
conf/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/u01/accts/a.brlamore/tmp/hadoop-datastore/hadoop-${user.name}</value>
<description>A base for other temporary directories. Default location /tmp/hadoop-${user.name}. Suggested Location /tmp/hadoop</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://ali-graph001.devapollogrp.edu:8020</value>
<description>The name of the default file system. This specifies the NameNode</description>
</property>
</configuration>
Set values in conf/hdfs-site.xml
<configuration>
<!--
<property>
<name>dfs.name.dir</name>
<value>/u01/accts/a.brlamore/tmp/path/to/namenode/namespace/</value>
<description>Where the NameNode metadata should be stored. Default location is ${hadoop.tmp.dir}/dfs/name. Suggested location /home/hadoop/dfs/name</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/u01/accts/a.brlamore/tmp/path/to/datanode/namespace/</value>
<description>Where DataNodes store their blocks. Default location ${hadoop.tmp.dir}/dfs/data. Suggested location /home/hadoop/dfs/data</description>
</property>
-->
</configuration>
Set values in conf/mapred-site.xml
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>ali-graph001.devapollogrp.edu:8021</value>
<description>Host or IP and port of JobTracker</description>
</property>
</configuration>
Hadoop Startup
# Format the filesystem
bin/hadoop namenode -format
# Start the HDFS on the NameNode
bin/start-dfs.sh
# Start Map-Reduce on the TrackerNode
bin/start-mapred.sh